
카테고리, 부서 같이 계층형 구조로 표현되어야 하는 모델을 계층형 모델이라고 한다.
계층형 모델을 표현하는 2가지 방법을 공부해보았다.
인접 모델(Adjacency List Model)

가장 간단하게는 이렇게 표현할 수 있다. 자식 노드에서 부모를 알고 있는것이다.
CREATE TABLE category (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
level integer not null,
parent_id integer,
foreign key (parent_id) references category(id)
);

자식 노드인 니트는 상의의 id를 알고 있고, 상의는 부모 노드 옷의 id를 알고 있다.
니트의 계층 구조는 옷 > 상의 > 니트 이렇게 표현할 수 있을것이다.
평범한 이커머스처럼 카테고리를 클릭하면 카테고리 경로, 카테고리의 하위 카테고리를 보여주는걸 구현한다고 생각해보자. (예제는 Django로 구현하였다.)
class Category(models.Model):
name = models.CharField(max_length=20)
level = models.IntegerField(default=1)
parent = models.ForeignKey("self", on_delete=models.CASCADE, null=True)
def __str__(self):
return self.namedef get_category_path(category: Category) -> list[str]:
if category.parent is not None:
paths = get_category_path(category.parent)
paths.append(category.name)
return paths
return [category.name]
def get_children(category: Category) -> QuerySet[Category]:
return Category.objects.filter(parent=category)
하위 카테고리는 상위 카테고리를 알고 있다는 점을 이용해서 깔끔하게 구현할 수 있다. 이렇게 하면 사람이 이해하기 쉽고, 깔끔한 코드로 로직을 작성할 수 있다.
하지만 계층이 깊어지거나, 카테고리의 경로를 구하는 유즈 케이스가 많아진다면 문제가 생길 수 있다. 우선 경로를 구하는 get_category_path 함수를 보면 재귀로 이루어져있다. 재귀 함수가 호출되고 category.parent.name을 참조할때마다 추가 쿼리가 실행될 것이고, 계층이 깊어질 수록 수행되는 쿼리의 수도 늘어나고, 메모리도 많이 차지하게 된다.
MPTT 모델(Modified Preorder Tree Trevarsal)
MPTT는 수정된 전위순회 트리 순회 알고리즘을 사용한 모델으로 트리 구조의 전위순회로 계층형 구조를 표현한것이다.
Preorder Tree Trevarsal란 Root -> Left -> Right 로 순회하는 것을 말한다.
계층형 구조를 트리로 표현해보고, 전위 순회로 번호를 매긴다. 여기서 기존의 Preorder Tree Trevarsal과 다른 점은 노드에 left, right로 번호를 매긴다는것이다.
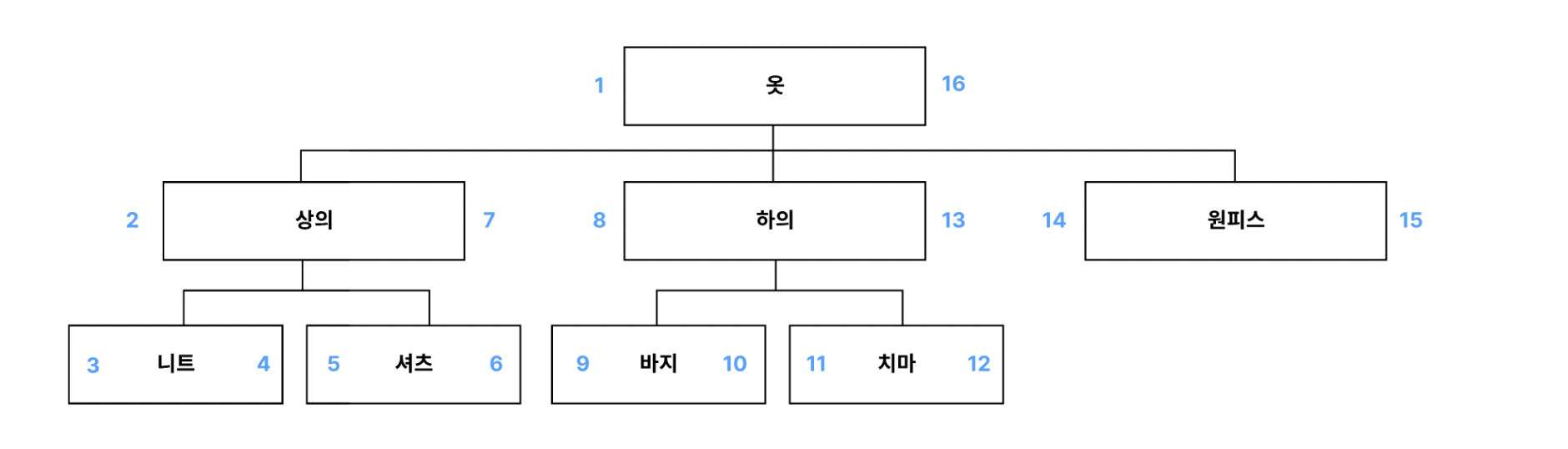
이러한 MPTT 모델은 두가지 특징을 가진다.
- 노드의 left 값은 항상 상위 노드의 left 값보다 크며, right 값은 항상 상위 노드의 right 값보다 작다.
- 모든 리프노드는 right = left + 1이다.
left값과 right값을 이용하여 최소한의 쿼리를 사용할 수 있다.
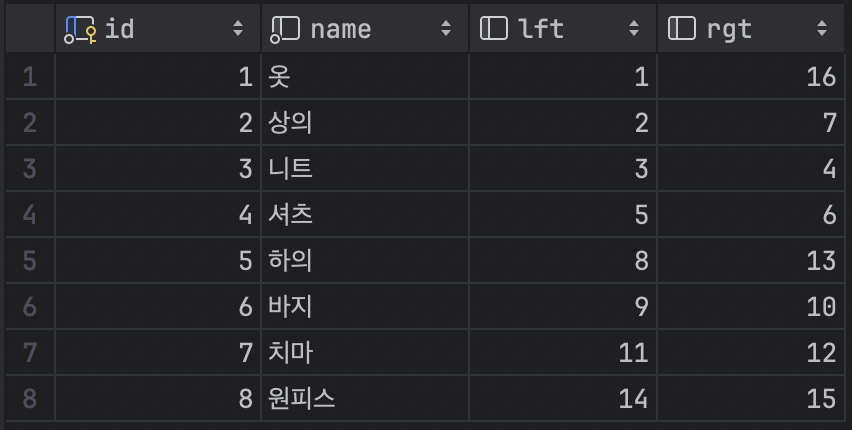
class CategoryMPTT(models.Model):
name = models.CharField(max_length=20)
lft = models.IntegerField(default=1)
rgt = models.IntegerField(default=2)
def __str__(self):
return self.name
@property
def size(self):
return math.floor((self.rgt - self.lft + 1) / 2)
@property
def is_leaf(self):
return self.rgt == self.lft + 1
@property
def paths(self):
return (CategoryMPTT.objects.only('name').filter(lft__lte=self.lft, rgt__gte=self.rgt).
order_by('lft').values_list('name', flat=True))
카테고리의 depth가 얼마나 깊든 하나의 쿼리로 조회할 수 있다.
insert / update는 어떻게 해야할까?
MPTT 모델은 조회할때는 간편하지만, 삽입, 수정이 복잡한 단점이 있다.
만약 바지(9, 10)와, 치마(11, 12) 사이에 새로운 카테고리 반바지를 삽입하는 경우는 어떻게 해야할까? 그림을 다시 그려보면, 반바지의 left, right는 11, 12가 될것이고, 그 이상의 노드들의 left, right가 이동할것이다.
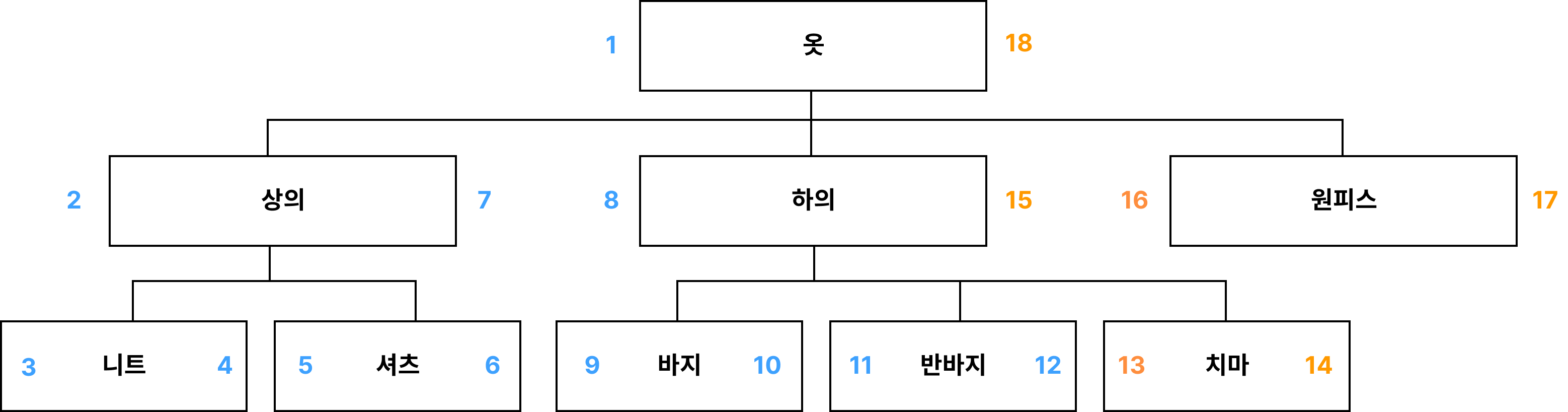
규칙을 찾아보면 이렇다. 삽입할 위치의 왼쪽 노드 반바지를 기준으로
- left가 10(바지의 right)보다 크면 left += 2 한다.
- right가 10(바지의 right)보다 크면 right +=2 한다.
- 반바지를 create(left=바지.right+1, right=바지.right+2)
리프 노드에 새로운 노드가 추가된다면?

이 경우에는 조금 다르다. 셔츠(5,6)밑에 새로운 노드가 추가되는것이므로 새로운 노드는 (셔츠의 left + 1, 셔츠의 left+2)이 될 것이다.
그리고 right가 5보다 크면 +2, left가 6보다 크면 +2를 해준다.
부모 노드인 셔츠를 기준으로
- right가 5보다 크다면(셔츠의 left) right += 2
- left가 6보다 크다면(셔츠의 right) left += 2
- 스트라이프 셔츠를 create(left=셔츠.left+1, right=셔츠.left+2)
이를 코드로 표현하자면 이렇게 표현할 수 있다. (리팩토링이 필요하다 😂 시간될때 리팩토링하고 갱신하는걸로)
def save_category(name: str, parent: CategoryMPTT = None):
if parent is None: # 루트 노드 추가
tree = CategoryMPTT.objects.aggregate(tree_size=Max('rgt'))
tree_size = tree['tree_size'] or 0
category = CategoryMPTT(name=name, lft=tree_size + 1, rgt=tree_size + 2)
category.save()
return category
elif parent.is_leaf: # parent에 신규 node를 추가하는 것이라면
new_lft = parent.lft + 1
new_rgt = parent.lft + 2
CategoryMPTT.objects.filter(lft__gt=parent.rgt).update(lft=F('lft') + 2)
CategoryMPTT.objects.filter(rgt__gt=parent.lft).update(rgt=F('rgt') + 2)
category = CategoryMPTT(name=name, lft=new_lft, rgt=new_rgt)
category.save()
return category
else: # parent 의 children 마지막에 node 추가
last_children = CategoryMPTT.objects.filter(lft__gt=parent.lft, rgt__lt=parent.rgt).order_by('lft').last()
CategoryMPTT.objects.filter(lft__gt=last_children.rgt).update(lft=F('lft') + 2)
CategoryMPTT.objects.filter(rgt__gt=last_children.rgt).update(rgt=F('rgt') + 2)
category = CategoryMPTT(name=name, lft=last_children.rgt + 1, rgt=last_children.rgt + 2)
category.save()
return category
이렇게 MPTT로 구현한 계층형 구조는 SELECT 할때는 편리하지만, INSERT, UPDATE 는 너무 복잡하다. 만약 같은 depth끼리 순서를 바꾸는 로직이 추가된다면? 더욱 더 복잡해질것이다.
결론
대부분의 서비스가 SELECT가 INSERT, UPDATE 보다 압도적으로 많으므로 계층형 구조에서 조회의 성능을 꼭 챙겨야한다면 MPTT를 고려해볼 수 있다.
하지만 MPTT는 INSERT, UPDATE할 때, 거의 전체 트리를 갱신해줘야하는 비용이 발생하며, 이는 트리의 크기가 커지면 커질 수록 더 비용이 많이 발생하게 된다.
개인적인 의견이지만 MPTT를 사용하고 싶으면 직접 구현하는것보단 잘 만들어져있는 라이브러리를 활용하는것을 추천하며, 인접 모델 조회 성능을 보완하는 다른 방법을 사용해서(캐시를 적용한다거나) 성능을 챙기는것이 더 좋은 방법인것 같다.
참고
이 글에 사용된 쿼리는 이 아티클을 참고하였습니다.
https://mikehillyer.com/articles/managing-hierarchical-data-in-mysql/
Managing Hierarchical Data in MySQL — Mike Hillyer's Personal Webspace
Introduction Most users at one time or another have dealt with hierarchical data in a SQL database and no doubt learned that the management of hierarchical data is not what a relational database is intended for. The tables of a relational database are not
mikehillyer.com
'기타' 카테고리의 다른 글
| Redis maxmemory와 eviction정책 (1) | 2024.06.19 |
|---|---|
| Lambda@Edge + Typscript로 이미지 리사이징 적용하기 (2) | 2024.06.05 |
| GraphQL Federation할때 null을 주의하자 (2) | 2024.03.12 |
| SQLD 합격 후기 (0) | 2023.12.21 |
| Serverless 배포할때 serverless update_rollback_failed state and can not be updated 에러가 나는 경우 (2) | 2023.10.09 |